
/*
本环境使用docker-elk搭建
*/
准备阶段
环境搭建
安装docker1
2curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
安装docker-compose:1.61
pip install docker-compose==1.6
clone docker-elk代码1
git clone https://github.com/deviantony/docker-elk.git
于docker-elk目录使用1
docker-compose up
[!] 如果遇到invalid reference formation分别修改1
2
3
4/elasticsearch/Dockerfile
/logstash/Dockerfile
/kibana/Dockerfile
除第一行ARG ELK_VERSION以外的ELK_VERSION 修改为6.5.2
window及其其他环境下参考—-官方文档:https://github.com/deviantony/docker-elk
汉化kibana
1 | docker ps -a #找到kibana的docker 容器id |
ps:6.5.2暴毙,很不巧的是,我所使用环境也是6.5.2
导入阶段
创建ES
创建索引1
curl -H 'Content-Type: application/json' -XPUT '127.0.0.1:9200/14e' -d '{}'
创建映射(6.x后移除string类型,index变为boolean)1
2
3
4
5
6
7
8
9
10
11
12curl -H 'Content-Type:application/json' -XPUT '127.0.0.1:9200/14e/data0/_mapping' -d '{
"data0": {
"properties": {
"email": {
"type": "text"
},
"passwd": {
"type": "text"
}
}
}
}'
设置logstash清洗,导入
设置/docker-elk/logstash/pipline/logstash.conf1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26input {
tcp {
port => 5000
}
}
filter {
mutate{
split => ["message",":"]
add_field =>{
"email" => "%{[message][0]}"
}
add_field =>{
"passwd"=> "%{[message][1]}"
}
remove_field => ["path","message","host","@version","port"]#去掉一些不想显示的字段
}
}
output {
elasticsearch {
hosts => "elasticsearch:9200"
index => "14e"
document_type => "data0"
}
}
index_type字段已改,大坑:https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html#plugins-outputs-elasticsearch-document_type
关于分割参考官网文档:https://www.elastic.co/guide/en/logstash/current/plugins-filters-split.html
logstash详细写法参考此文章:https://doc.yonyoucloud.com/doc/logstash-best-practice-cn
nc 传入数据1
nc localhost 5000 < 0
nc 批量传入1
nc localhost 5000 < ./*
静候载入。
建立图表分析
create pie->split slices
split slices下的sub Aggregation选择filters
分别添加filters1
email:"xxxx.xx"
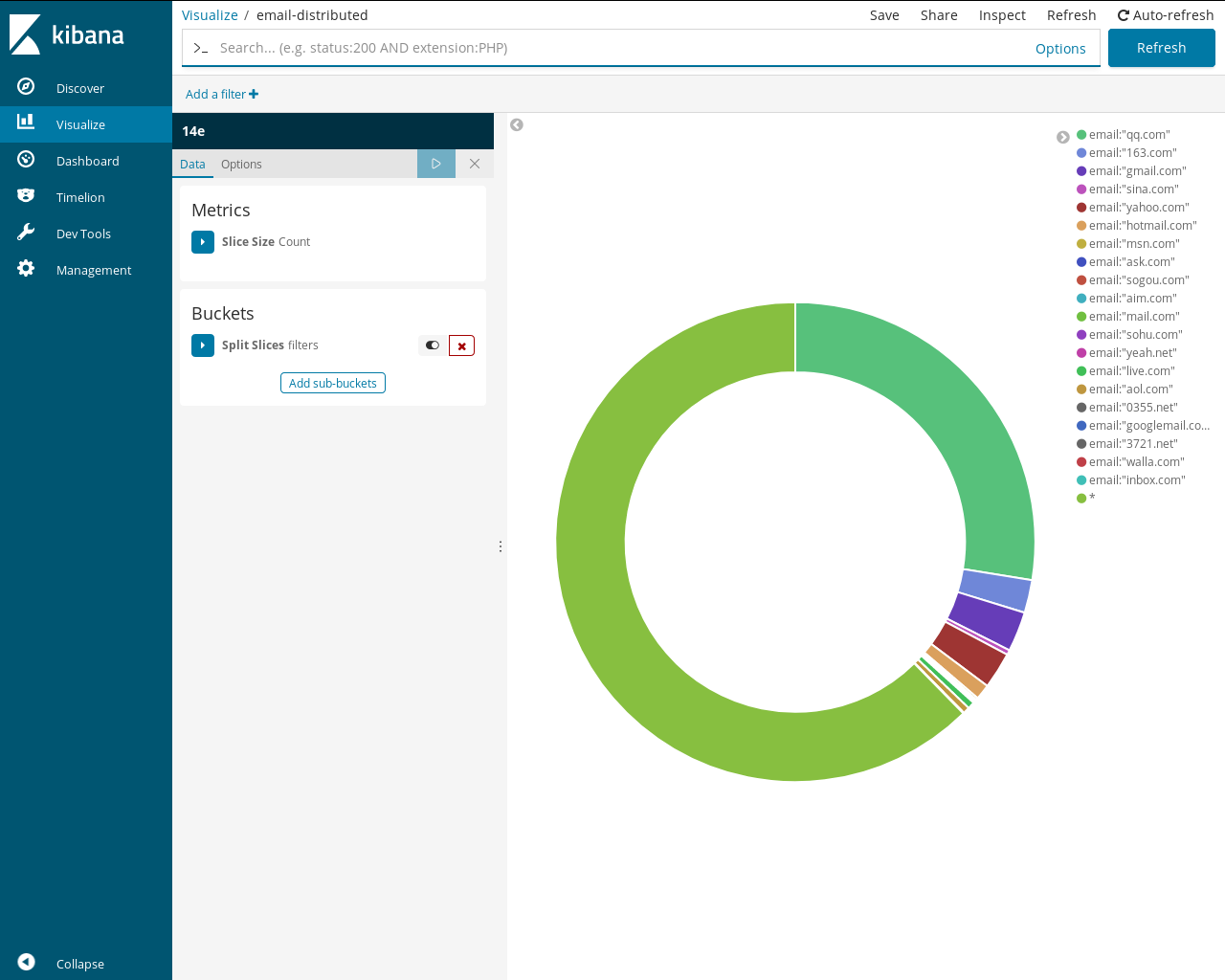
后续
logstash对于空字段未经判断=>导致passwd出现%{[message][1]}
\ux15等乱码字符未处理
数据还没导完..
其他功能还没试玩..